This week RStudio v1.2 was released. The newest version of the popular IDE has support for the supercool reticulate package which allows us to run Python chunks in R notebooks.
Getting started is as simple as loading reticulate and replacing the chunk ```{r} # Your R code here ``` with ```{python} # Your Python code here ```. Furthermore, reticulate has support for loading Python environments. In the example below, I access a conda environment named ml that contains all my machine learning modules.
# This is an R chunk
library(reticulate)
use_condaenv("ml")# This is a Python chunk
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from collections import OrderedDict
sns.set_style('whitegrid')
sns.despine(right=True, top=True)In the following I’ll post my proposed solutions to The Riddler, the puzzle column of the data-driven news site and brain-child of celebrity-statistician Nate Silver, FiveThirtyEight. The Riddler typically consists of an “express” challenge and a “classic” challenge. I usually code these in Python, and thanks to reticulate I can now share them here. The following proposed solutions are for the March 29th puzzle.
The Riddler Express
“You are playing your first ever game of “Ticket to Ride,” a board game in which players compete to lay down railroad while getting so competitive they risk ruining their marriages. At the start of the game, you are randomly dealt a set of three Destination Tickets out of a deck of 30 different tickets. Each reveals the two terminals you must connect with a railroad to receive points. During the game, you eventually pick up another set of three Destination Tickets, so you have now seen six of the 30 tickets in the game.
Later, because you enjoyed it so much, you and your friends play a second game. The ticket cards are all returned and reshuffled. Again, you are dealt a set of three tickets to begin play. Which is more likely: that you had seen at least one of these three tickets before, or that they were all new to you?"
total_cards = 30
new_cards = 24
prob_new_card = lambda k: (new_cards - k) / (total_cards - k)
prob_all_new = 1
for i in range(3):
prob_all_new *= prob_new_card(i)
# Probability of being dealt three previously unseen cards: 0.4985
# Probability of having seen at least one of the cards before: 0.5015The Riddler Classic
"You are competing in a spelling bee alongside nine other contestants. You can each spell words perfectly from a certain portion of the dictionary but will misspell any word not in that portion of the book. Specifically, you have 99 percent of the dictionary down cold, and your opponents have 98 percent, 97 percent, 96 percent, and so on down to 90 percent memorized. The bee’s rules are simple: The contestants take turns spelling in some fixed order, which then restarts with the first surviving speller at the end of a round. Miss a word and you’re out, and the last speller standing wins. The bee words are chosen randomly from the dictionary.
First, say the contestants go in decreasing order of their knowledge, so that you go first. What are your chances of winning the spelling bee? Second, say the contestants go in increasing order of knowledge, so that you go last. What are your chances of winning now?"
Original solution
Spelling bees aren’t really a thing where I’m from, so in the first iteration of my solution I made the assumption that a round ends when a contestant gets a word wrong. The next round then starts with the player immediately following the recently eliminated contestant. This led to some experimentation with ordered dictionaries and reshuffling lists. I also wanted to get a distribution of the estimated win rate for the best player, so I ran the multiple simulations.
def spelling_bee_winners(players, best_player_starts=True, num_bees=10**3, to_percent=False):
''' Simulate spelling bees and return distribution of victories.'''
results = {name: 0 for name in players}
# Simulate spelling bee
for i in range(num_bees):
names = players.copy()
probs = [.9 + 0.01*i for i in range(10)]
if best_player_starts:
probs = probs[::-1]
else:
names = names[::-1]
spelling_bee = OrderedDict([(name, prob) for name, prob in zip(names, probs)])
# This is a round, restarts when player gets eliminated
while len(spelling_bee) > 1:
for player, prob in spelling_bee.items():
# Sample a word from the dictionary
word = np.random.uniform(size=1)
# If player doesn't know word, remove from competition, reorder contestants and start new round
if word > prob:
remove = names.index(player)
del names[remove]
del probs[remove]
# Check if eliminated player is the last player
if len(names) - remove == 1:
spelling_bee = OrderedDict([(name, prob) for name, prob in zip(names, probs)])
break
else:
new_players = names[remove:] + names[:remove]
new_probs = probs[remove:] + probs[:remove]
spelling_bee = OrderedDict([(name, prob) for name, prob in zip(new_players, new_probs)])
break
# Record victory for winning player
for player in spelling_bee.keys():
results[player] += 1
# Convert score to percent
if to_percent:
for player in results.keys():
results[player] = results[player] * (1 / num_bees)
return results
def simulations(players, num_bees=10**3, simulations=100, best_player_starts=True, to_percent=False):
''' Simulate spelling bees to get average and std. deviations. '''
results = np.zeros(simulations)
for i in range(simulations):
best_first = spelling_bee_winners(players, best_player_starts=best_player_starts, num_bees=num_bees, to_percent=to_percent)
results[i] = best_first['A']
return results
def plot_results(results, bins=20, label=None):
''' Helper function to plot results of simulations.'''
average = round(np.mean(results), 4)
plt.hist(results, bins=bins, alpha=0.7, label=f'{label} (avg.: {average})')
plt.axvline(average, linestyle="--", color='k')
# Simulating spelling bees
players = ["A", "B", "C", "D", "E", "F", "G", "H", "I", "J"]
best_first = simulations(players, best_player_starts=True, to_percent=True)
best_last = simulations(players, best_player_starts=False, to_percent=True)
# Plotting comparisons
plt.figure(figsize=(8, 6))
plot_results(best_first, label='First player')
plot_results(best_last, label='Last player')
plt.title('Starting first vs. starting last', size=20)
plt.legend()
plt.show()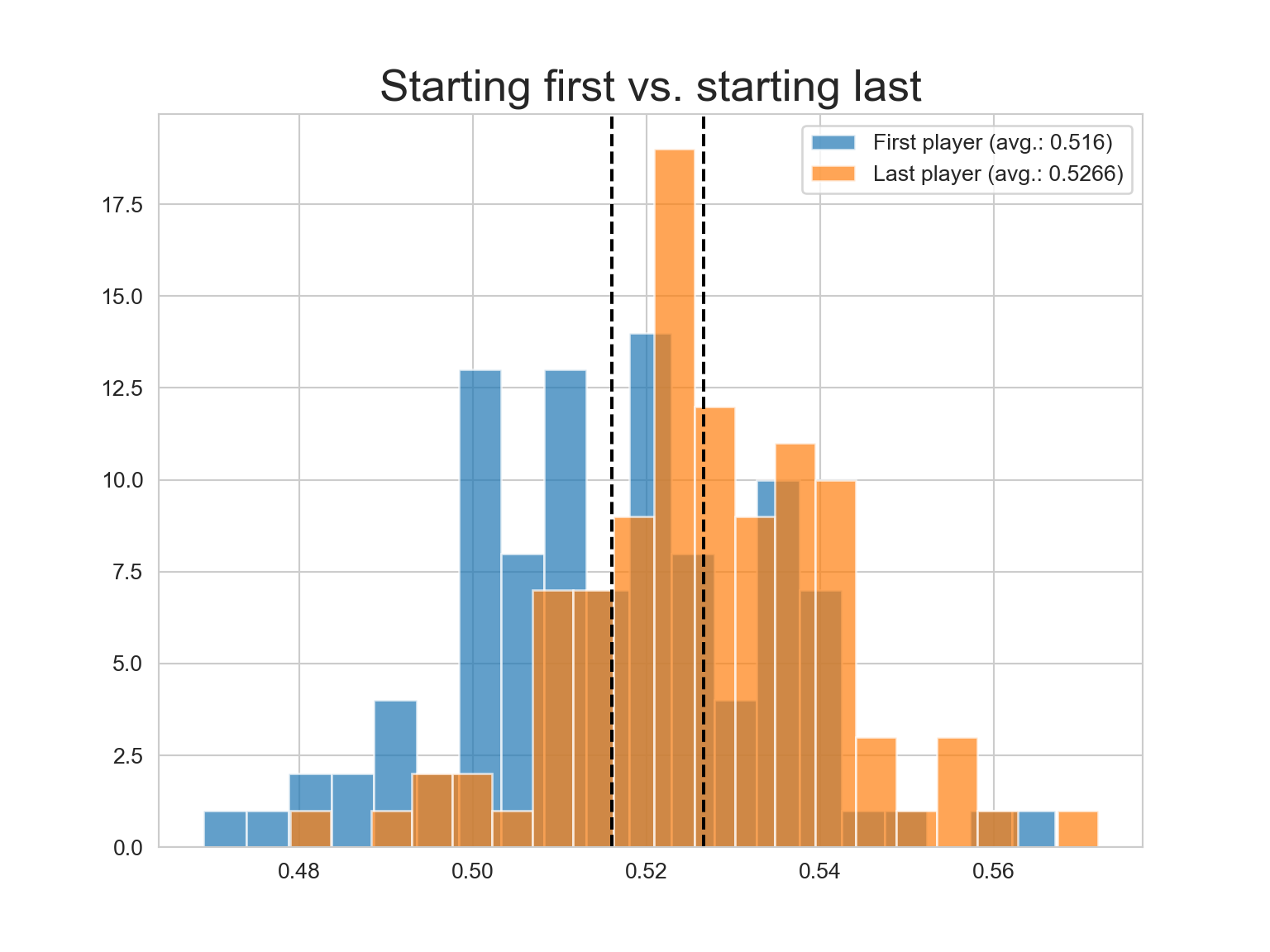
So it turns out the the order of the contestants doesn’t really matter that much. The most knowledgable player slightly increases her probability of winning if she goes last.
Revised solution
As it turns out, I think I overcomplicated the rules of elimination somewhat due to the fact that I don’t really know how a spelling bee works. I quite like this approach by Josh Nees, so I decided to write my own variant of it. His is a cleaner implementation than my original proposal, the only thing I added was the potential outcome where all players get a word wrong and the game ends in a tie.
def spelling_bee_winners(players, best_player_starts=True, num_bees=10**3, to_percent=False):
''' Simulate spelling bees and return distribution of victories.'''
results = {name: 0 for name in players}
ties = 0
# Simulate spelling bee
for i in range(num_bees):
contestants = players.copy()
if best_player_starts:
contestants = contestants[::-1]
# This is a round, restarts when player gets eliminated
while len(contestants) > 1:
for contestant in contestants:
# Sample a word from the dictionary
word = np.random.randint(0, 101, size=1)
# If player doesn't know word, remove from competition, reorder contestants and start new round
if word > contestant:
contestants.remove(contestant)
# If all contestants fail, the round ends in a tie
if len(contestants) == 0:
ties += 1
# Record victory for winning player
else:
results[contestants[0]] += 1
# Convert score to percent
if to_percent:
results = {player: (score / num_bees) for player, score in results.items()}
return results, ties
# Simulating spelling bees
players = [i for i in range(90, 100)]
num_bees = 500000
best_first, _ = spelling_bee_winners(players, best_player_starts=True, num_bees=num_bees, to_percent=True)
# Probability of winning: 0.512562
best_last, _ = spelling_bee_winners(players, best_player_starts=False, num_bees=num_bees, to_percent=True)
# Probability of winning: 0.519574Other approaches
I came across this really compact and nice solution by Jason Ash. He has some other very elegant Riddler-solutions, be sure to check out his blog. The following code is lifted directly from Jason’s site:
def single_round(spellers):
"""
Play a single round of the spelling bee; draw a random number for each speller,
then compare the number vs. their rate. Each speller that answers correctly
is retained in the array, while incorrect spellers are removed. Returns a new
array of the spellers that advance to the next round.
NOTE : if the function would return an empty array, (in the case that every speller
failed to spell the word correctly) it instead returns the speller listed last in
the original array, who would have won without having to spell a word.
"""
r = np.random.rand(len(spellers))
out = spellers[r < spellers]
if len(out) > 0:
return out
else:
return spellers[-1:]
def bee(spellers):
"""
Run a spelling bee with as many rounds as it takes to eliminate all but one
speller.
"""
while len(spellers) > 1:
spellers = single_round(spellers)
return spellers[0]
def model(spellers, trials):
"""
Run any number of spelling bees and return the winner for each one.
Results returned as a numpy array.
"""
return np.array([bee(spellers) for _ in range(trials)])
def summary(spellers, trials):
"""
Return a dictionary with key=speller, value=wins from the simulated results
NOTE : the order of "p" matters, because the last speller has an advantage
each round. However, the results are shown after sorting the array from
lowest to highest so that different orders of "p" can be compared easily.
"""
results = model(spellers, trials)
return {x: sum(results == x) / trials for x in np.sort(spellers)}Very cool!